Memory Request Optimizer Stream Benchmark Results
November 26th, 2016 by Gregg Recupero
Overview
The Memory Requests Optimizer is designed to improve the performance of your memory sub-system. It does this by reducing latency and increasing bandwidth. We thought it would be very interesting to run the Stream Memory benchmark utilizing the Memory Request Optimizer. The impressive results of this experiment are described below.
System Analysis: Performance-IP Memory Request Optimizer
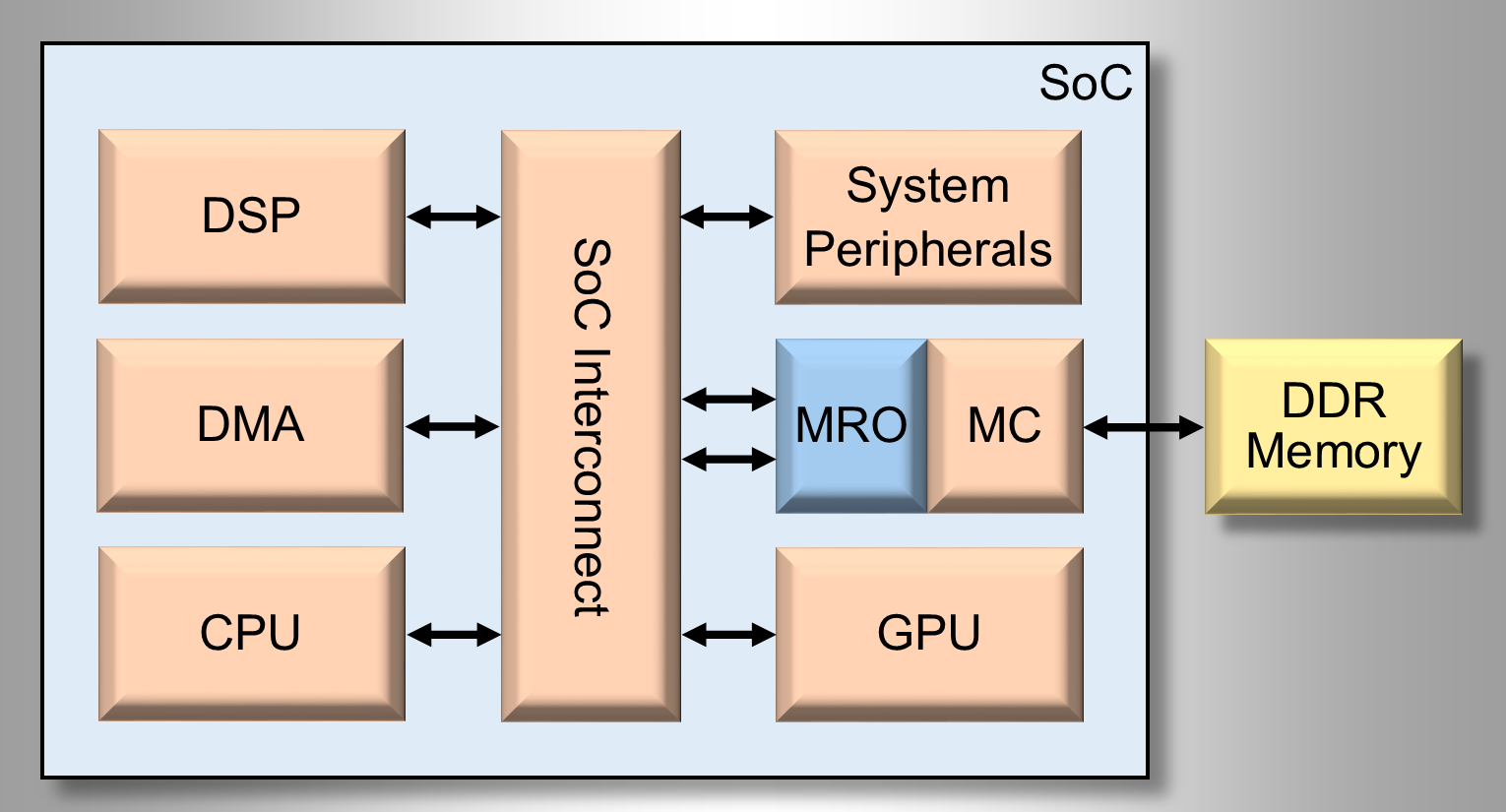
The MRO can be implemented at any point of the memory hierarchy and for any number of clients. For our Stream Benchmark analysis, we implemented the SoC shown in Figure 1. Placing the MRO directly in front of the Memory Controller. In our example, the CPU was implemented with a 32b RISC processor running at 125MHz and had a 64b data bus connected to the SoC interconnect. Requests to external memory required only 25 clock cycles to complete. Even modeling the subsystem with only 25 cycles of latency the Performance-IP MRO analysis yielded unprecedented results.
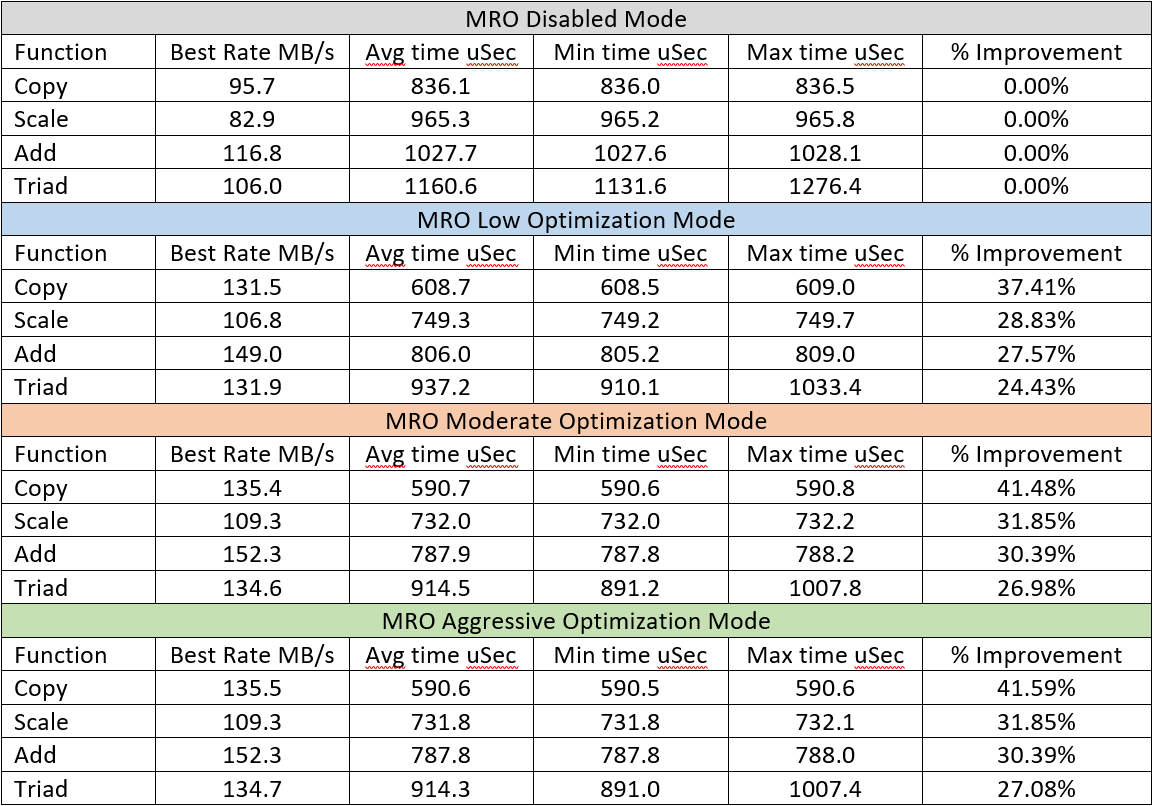
MRO - Stream Memory Benchmark Results
The industry standard Stream Memory Benchmark is a program that measures sustainable memory bandwidth. Because the MRO is designed to reduce memory latency and increase bandwidth, we were very excited to run this application with the MRO. This would show how the improved BW and reduced latency numbers translate in to higher Instructions Per Cycle (IPC) and Millions of Floating Point Operations (MFLOPS). First, we ran the Stream benchmark with the MRO disabled to determine the system baseline. We than re-ran the benchmark using the three different modes of optimization provided by the MRO. This application experienced dramatic reductions in latency of 71%, 77%, and 78% across the three different modes MRO of operation. These reductions produced the IPC and MFLOPS percent increase for each MRO mode shown in Table 1.

The improved IPC and MFLOPS generated large increases in the Copy, Scale, Add, and Triad Stream benchmarks. The Steam benchmark results can be seen in Table 2. In this table, MRO Disabled Mode is our baseline. In this mode requests pass directly through the MRO to the memory controller, unaffected. Then we have the MRO results for each of the three progressive optimization modes.