
High Performance Memory Sub-Systems
October 19th, 2015 by Gregg Recupero
Introduction
Memory bandwidth had set the limits of compute performance over the past several decades. As processor and system performance has continued to increase at almost exponential rates, memory performance has struggled to keep up with that pace. This is all about to change.
The new emerging memory standards all promises that they will shatter the memory bandwidth limits that have plagued the computer landscape. High Bandwidth Memory, Hybrid Memory Cube, and the Wide IO standards can dramatically increase memory bandwidth, delivering unprecedented performance levels for next generation compute platforms. However, with all good architectural design, system performance will still be limited by the weakest link. Therefore, when SoC architects are designing their next generation platforms, every component in the memory sub-system will be important for higher overall system performance.
Solution
At Performance-IP we understand this requirement and have incorporated support for high bandwidth/low latency interfaces in all our IP, allowing our memory sub-systems IP to deliver the highest possible performance to our customers systems.
Our L2+ Cache product is designed to support the advanced features that system architects require. Support for multiple hit-under-miss, and miss-under-miss operation allows our L2+ Cache to deliver an uninterrupted stream of read response data to requesting clients. Figure 1 below, shows client requests presented every cycle to the L2+ Cache. Responses that hit and miss the cache are interleaved to the requesting client in a continuous stream of responses. This allows the L2+ Cache to issue read response data on every clock cycle, delivering the maximum bandwidth to the requesting clients.
Figure 1 - Single Client Bandwidth Performance
The L2+ Cache can be configured to support systems with multiple clients. The high-performance multi-client support allows the cache bandwidth to scale with the addition of more clients, increasing the deliverable bandwidth by the number of clients. In Figure 2 below, we see how the L2+ Cache can issue multiple read responses to different clients in parallel. Demonstrating the ability to scale read bandwidth by the number of clients.
Figure 2 - Multi-Client Bandwidth Performance
For system architects that require the ultimate in system performance we offer the L2+ Cache Multi-Bank/Multi-Client implementation. In a similar fashion to the Multi-Client configuration scaling the available client bandwidth over the Single-Client implementations. The Multi-Bank configuration then scales available client bandwidth across multiple cache banks. Figure 3, demonstrates how multi-clients configured in a multi-bank implementation can issue concurrent read responses providing the highest available system read bandwidth to clients.
Figure 3 - Multi-Bank/Multi-Client Bandwidth Performance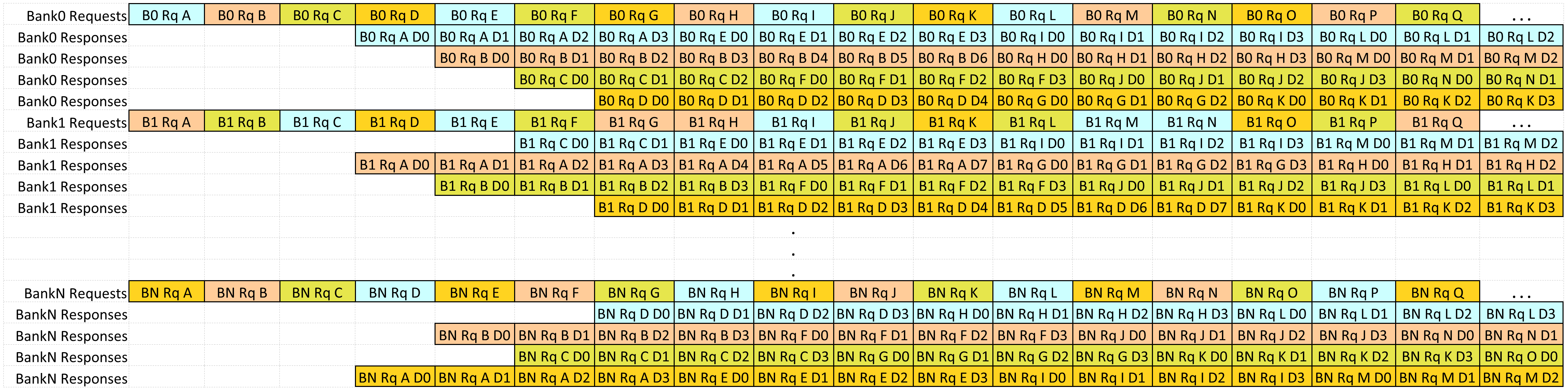
Conclusion
Performance-IP's L2+ Cache is both configurable and scalable. This allows the SoC architect to implement the required number of banks and client interfaces to best match system requirements. When Performance-IP's cache solutions are combined with an on-chip network unprecedented performance can be delivered to your system. Whether you are designing for today's DDR4 or next generation memory standards. Products from Performance-IP, will make the most of your memory sub-system. That is the Performance-IP difference.
In our next segment we will look at our patent-pending Memory Tracker Technology™ and how it improves cache hit rates.